
Let me tell you about a problem that shouldn’t exist in 2025.
You receive a PDF. It’s a property listing—maybe a sleek Tokyo apartment flyer, maybe a scanned photocopy from a rural agent’s fax machine. Your job? Get that information into your database. Simple, right?
Wrong.
The OCR Trap
If you’ve spent any time trying to digitize real estate documents at scale, you’ve probably tried the usual suspects. Google Cloud Vision, AWS Textract, maybe even good old Tesseract if you’re budget-conscious. These tools are impressive—genuinely. They can read text from images with remarkable accuracy. Some can even handle tables and forms.
But here’s where they all fall short: they don’t understand what they’re reading.
Hand any OCR tool a Japanese property flyer and you’ll get back a blob of text. Somewhere in there is the price (¥45,000,000), the land area (120.5㎡), the walking distance to the station (徒歩8分), and probably someone’s phone number. Good luck programmatically figuring out which is which. Was that number the price or the building age? Is that the land area or the floor area ratio? Your OCR tool doesn’t know. It doesn’t care. It just gave you text.
Template-based extraction tools try to solve this by mapping specific regions of a document to specific fields. Great—until the layout changes. Until you get a document from a different agency. Until someone decides to add a decorative border or rearrange the floor plan. Suddenly, your carefully configured templates are useless, and you’re back to manual data entry.
What We Actually Needed
We needed a system that could do what a human does: look at a property listing and understand it. Not just read it, but interpret it. Know that the big number at the top with the yen symbol is probably the price. Recognize that a grid of rectangles labeled “1LDK” is a floor plan. Understand that “徒歩5分” means “5-minute walk” and extract that as structured data, not just random characters.
And we needed it to work across different layouts, different agencies, different quality scans, and yes—different languages.
So we built it.
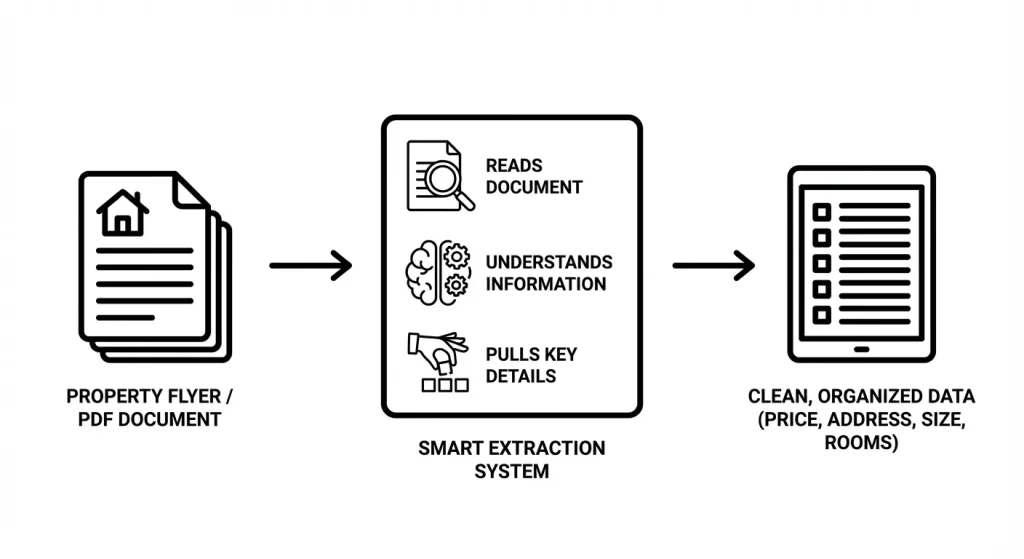
How It Actually Works
Our system isn’t revolutionary in its components—it’s smart in how it combines them. We use OCR (because you still need to pull text from images), but then we feed both the image and the extracted text into a multimodal AI model. Currently, we’re using Gemini, though the architecture is flexible enough to swap models as better ones emerge.
The AI doesn’t just parse text—it interprets the entire document visually and contextually. It sees the layout. It understands Japanese real estate conventions. It knows what matters and what doesn’t.
For critical fields where precision is non-negotiable—price, area measurements, floor area ratios—we layer on deterministic text extraction as a safety net. AI is smart, but regex doesn’t hallucinate numbers.
The output? Clean, standardized JSON. Every time. Same schema, same field names, whether we’re processing a glossy corporate listing or a hand-scanned flyer from 1995. Missing data gets marked as null, not silently dropped or inconsistently formatted.
We even throw in optional geocoding (because latitude/longitude beats vague address descriptions) and automatic translation to English, so international teams can work with Japanese listings without constantly context-switching.
The Honest Part: It’s Not Perfect
Look, I could write another five paragraphs about how amazing this system is, but let’s be real—it’s not flawless.
Sometimes unusual layouts confuse it. Low-quality scans can cause problems. Geocoding occasionally chokes on weirdly formatted addresses. There are edge cases we haven’t built for yet, compliance considerations we’re intentionally not tackling right now, and obscure document formats we simply don’t support.
But here’s the thing: we’re okay with that.
Perfect is the enemy of shipped. This system handles 95% of our real-world documents with zero human intervention. That remaining 5%? We can handle those manually—and we still come out way ahead compared to processing everything by hand or fighting with brittle template systems.
The stuff we’re not handling yet—deep legal compliance automation, every possible document variant, bulletproof handling of truly terrible scans—those are future problems. Important problems, but not blockers. We’ll get there. For now, this system does what matters: it saves our team dozens of hours every week, scales effortlessly, and turns chaotic PDFs into usable data.
Why This Matters
If you’re in real estate tech, you know the frustration. Every property listing is data you need to extract, validate, and standardize before you can do anything useful with it. That bottleneck—between receiving a listing and having it live on your platform—is where deals slow down, where opportunities get missed, where someone’s time gets wasted on data entry instead of actual work.
We built this system because we were tired of that bottleneck. Tired of choosing between expensive-but-limited SaaS tools and open-source-but-barely-adequate libraries. Tired of documents that were technically digitized but practically unusable.
If you’re facing the same problem, maybe this approach helps. Or maybe you’ll build something different—something better, even. Either way, the goal is the same: stop fighting with your documents and start using them.